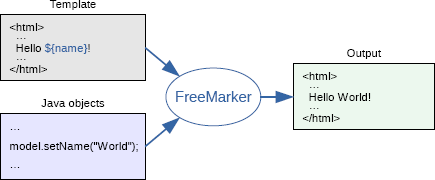
I am using Mercurial since about half a year pretty regularly and I am also (forced) to use GIT recently. And I must say, that I am not pleased with the GIT experience at all. An initial statement first, though: I am not arguing about features here; it is no doubt, that GIT is an extremely powerful and also reliable sourcecode management system. But the user experience is, in my opinion, questionable at least.
The first time I got into contact with distributed SCM systems was through Mercurial. There are some new concepts that have to be understood (coming from Subversion), but generally spoken it is pretty easy to start with. Simple things are simple, complex things are mostly reasonable to understand. The basic set of commands and switches is kept simple and are hence easy to learn and understand. One is not flooded with commands and options in the beginning; specific functions (e.g. patch queues, rebasing, ...) can be switched on later by enabling the very extension. About 35 extensions are part of the Mercurial distributions and can be enabled by adding one line to the config file. Other extensions can be installed when needed.
In my opinion, this is a very clever way to hide unecessary complexity in the beginning and to provide the new user with a clean and simple set of commands. Later on, enabling specific extensions allow a "fine-tunes" feature set. Along comes a concise but pretty good help documentation. One example: "hg help log" explains the log command in about one screen page.
The first encounter with GIT on the other hand is in my opinion rather terrible. Try "git help log" and you get around 20 (sic!) screens with Unix-style documentation (and this is not meant as a compliment) of the log command. There is a lot of documentation on the GIT homepage though. But there are a lot of other "goodies" in the man pages as well. One more example?
Well: "hg glog" shows me a representation of the history of my repository including branches. "git log" does only show the current branch. OK, so there should be an option to control that. Well, first of all: good luck with 20 man pages... Then I searched for "/branch" in the man-page and found the "--branches" switch (which apparently does the job). Yet what do I find as explanation of this switch?
--branches: Pretend as if all the refs in $GIT_DIR/refs/heads are listed on the command line as.
I am a very peaceful character, but honestly, when I read such a statement in a documentation, I feel the urgent need rising to beat the developer who wrote that line.
The Git community book that is (according to the website) "meant to help you to learn how to use GIT as quickly and easily as possible" start in the first chapter with a detailed explanation of the internal GIT data model instead of explaining fundamental principles of DSCM und Git. WTF? To be fair, there is a set of other documentation artefacts on the website that appear to be significantly better for starters though.
The Git community book that is (according to the website) "meant to help you to learn how to use GIT as quickly and easily as possible" start in the first chapter with a detailed explanation of the internal GIT data model instead of explaining fundamental principles of DSCM und Git. WTF? To be fair, there is a set of other documentation artefacts on the website that appear to be significantly better for starters though.
The main issue in my point of view, all considered, is the lack of encapsulation/layering of functionality. What is done great in Mercurial (e.g. with extensions) is done very bad in GIT. My feeling with GIT is, that there is at least one level of abstraction too few in the design. The user experience reminds me to the less good student projects I have seen over the years: In many of these projects there is no need to take a look at e.g. the ER diagram or database schema: a glance at the GUI is sufficient. Each database table is represented in the GUI, probably separated by "tabs". "Great" design: all internals layed out to the user, who is usually not interested in technical details, but in solving a specific (higher level) problem.
I got a similar feeling with GIT: no doubt it is technically on a very (!) different level than the mentioned student projects, but the usability feels pretty much the same. With nearly every interaction I have not the impression of solving my SCM problem, but interacting with technical details I am not actually interested in. It feels like cars in the 1920 (or Vespas in the 90s), you spend more time under the hood fixing some crap then driving to your destination.
I really hope, that the GIT team is going to improve the user interface. in the future. Allowing low-level ("assembler commands") for specific purposes and experts and a significantly better abstracted set of commands for "day to day" operations. Consequentially, at the moment, I would definitly recommend Mercurial over GIT, simply by the much better user experience and layering/abstraction of functionality.
p.s.: 5min after I wrote this article, I figured, that Martin Fowler wrote an article yesterday about VCS;
p.s.: 5min after I wrote this article, I figured, that Martin Fowler wrote an article yesterday about VCS;